Why Your RAG System Gives Wrong Answers (And How to Fix It With Better Chunking)
.png)
Your AI assistant cites a policy that was updated six months ago. A customer-facing chatbot answers from the wrong document entirely. Your internal knowledge base returns confident, well-structured responses that are factually wrong.
The instinct is to blame the model. But in most cases, the model is not hallucinating. It is faithfully generating an answer from the context it was given. The real problem is upstream: it retrieved the wrong chunk.
This is not a fringe issue. According to a 2026 analysis by Faktion, naive RAG pipelines using fixed-size chunking with single-vector similarity search fail to retrieve the correct context roughly 40% of the time, with accuracy degrading further as document collections grow (Faktion, 2026). A separate VentureBeat report found that roughly 70% of teams running RAG in production have no systematic evaluation for retrieval quality (VentureBeat, 2026).
The gap between a RAG proof-of-concept and a production system that stakeholders can trust is almost always a retrieval problem. And the single biggest lever you have over retrieval quality is how you chunk your documents.
What most teams get wrong about chunking
Chunking is the process of splitting source documents into smaller pieces that get embedded and stored in a vector database for retrieval. It sounds mechanical, but the decisions you make here determine whether your RAG system retrieves the right context or the wrong one.
Three mistakes account for most retrieval failures.
1. Fixed-size chunks that split meaning
The most common default is to split documents into 500-token chunks with a small overlap. This is fast and simple, but it routinely cuts sentences, paragraphs, and arguments in half. A chunk that starts mid-thought and ends mid-thought cannot be meaningfully retrieved, no matter how good your embedding model is.
Unstructured.io’s RAG best practices guide puts it directly: fixed-size chunking is “a fine baseline and a poor ceiling” because it ignores document structure entirely (Unstructured, 2026).
2. No metadata or context preservation
When a chunk is retrieved, the model sees only that chunk. If the chunk does not carry its section heading, document title, date, or source identifier, the model has no way to assess whether the information is current, relevant, or from the right document. This is how a RAG system confidently answers from an outdated policy or the wrong department’s handbook.
3. One strategy for all document types
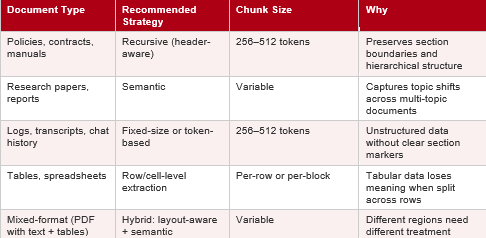
A legal contract, a product manual, a meeting transcript, and a financial report have fundamentally different structures. Applying the same chunking strategy across all of them guarantees poor retrieval for at least some of them. Research from Databricks’ technical blog confirms that structured documents perform best with recursive chunking, multi-topic documents benefit from semantic chunking, and unstructured data like logs and transcripts are better suited to fixed-size or token-based approaches (Databricks, 2025).
A practical chunking framework that actually improves retrieval
The following framework is not theoretical. Each recommendation comes with a concrete “do this, expect that” outcome. Start with whichever step addresses your biggest pain point, but the full stack compounds.
Use semantic boundaries, not arbitrary token counts
Semantic chunking groups sentences based on embedding similarity. When the cosine similarity between adjacent sentences drops below a threshold, a chunk boundary is placed. This means chunks align with actual shifts in topic rather than arbitrary character counts.
What to expect: Chroma’s research showed recursive chunking delivers 85–90% recall at 400 tokens, while semantic chunking reaches 91–92%, though at higher compute cost during ingestion (Firecrawl, 2026). For most teams, recursive chunking at 256–512 tokens is the practical sweet spot: validated in a February 2026 benchmark that placed recursive 512-token splitting first at 69% accuracy across 50 academic papers (LangCopilot, 2026).
Set overlap at 10–20% of chunk size
Overlap ensures that ideas spanning chunk boundaries are captured in at least one chunk. Industry consensus, re-validated in February 2026, recommends 10–20% overlap as a starting point: 50–100 tokens for a 500-token chunk (Redis, 2026).
What to expect: Overlap prevents the most common retrieval miss: the answer sits exactly at a chunk boundary and neither chunk captures the full thought. Too much overlap (>25%) creates redundant embeddings and inflates storage without improving recall.
Respect document structure
If your document has headings, sections, tables, or page breaks, your chunking strategy should use them as natural boundaries. A chunk should never start in one section and end in another. For structured documents like manuals, policies, and contracts, recursive chunking that splits at headers first, then paragraphs, then sentences, preserves meaning far better than flat tokenization.
Attach metadata to every chunk
Every chunk should carry: the source document title, section heading, page number or location, document date, and any relevant tags (department, product line, regulation). This metadata serves two purposes: it enables filtered retrieval (retrieving only from current documents, or only from a specific department’s policies), and it gives the model enough context to assess source relevance.
Use parent-child chunk relationships
Parent Document Retrieval is a strategy where you embed small, precise chunks for retrieval but return larger blocks of surrounding context to the model for generation. This gives you the best of both worlds: precise matching with rich context (SurePrompts, 2026).
What to expect: A 2025 study showed this approach improved retrieval accuracy by 12–18% on documents with heavy cross-references, such as legal contracts and technical manuals (LangCopilot, 2026).
How hybrid search and reranking amplify good chunking
Good chunking is the foundation, but it is not the whole retrieval stack. Once your chunks are well-formed, two additional layers compound the improvement.
Hybrid search: keyword + vector
Dense vector retrieval handles semantic paraphrase well but can miss exact-match queries: product codes, regulation numbers, named entities. BM25 keyword search handles those precisely but cannot understand paraphrase. Hybrid search runs both in parallel and fuses results using Reciprocal Rank Fusion (RRF), a rank-only algorithm that sidesteps score incompatibility between the two systems (Superlinked, 2026).
What to expect: VentureBeat reported that enterprise hybrid retrieval adoption tripled in Q1 2026, driven by production teams discovering that vector-only search was insufficient for precision-sensitive use cases (VentureBeat, 2026).
Reranking: the highest-ROI improvement
After initial retrieval returns a candidate set, a cross-encoder reranking model re-scores each document against the original query with full attention. Unlike bi-encoders used in initial retrieval, cross-encoders see the query and the document together, which produces much more accurate relevance judgments.
What to expect: Studies show cross-encoder reranking delivers +33–40% accuracy improvement for only +120ms latency on average. A 2026 benchmark on financial QA showed reranking improved MRR@3 by 39% (Ailog, 2025). Cohere Rerank 4 Pro achieved +170 ELO over v3.5, with +400 ELO specifically on business and finance tasks.
The Retrieval Stack (in order of impact)
1. Chunk well → 2. Retrieve hybrid → 3. Rerank aggressively → 4. Measure
How to measure if your retrieval is actually working
If you cannot measure retrieval quality, you cannot improve it. Yet roughly 70% of teams running RAG in production have no systematic eval (VentureBeat, 2026). The following five metrics give you a practical scorecard.
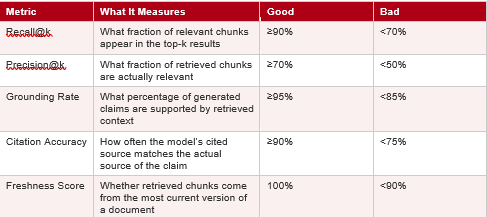
These metrics map to the three-layer evaluation framework described by FutureAGI and Confident AI: retrieval quality, generation quality, and end-to-end pipeline performance. A pipeline can succeed at retrieval but fail at generation (the model fabricates despite having the right context), or fail at retrieval but appear to succeed (the model generates a plausible-sounding answer from irrelevant chunks) (FutureAGI, 2026; Confident AI, 2026).
Action Item
Run a retrieval eval on 50 representative queries from your production traffic this week. If recall@10 is below 80%, your chunking strategy is the first thing to revisit.
What this looks like in production
The framework above is how we approach retrieval at Redpumpkin.ai. When we built an agentic AI pipeline for a major bank’s trade finance operations, document chunking and retrieval were the foundations that made everything else possible: vision-based extraction, agentic reasoning, and human-auditable decision chains.
The details of that deployment, including how we reduced document verification from 4 days to 15 minutes and achieved up to 98% anomaly detection accuracy are covered in our trade finance case study: Trade Finance Agentic AI: A Case Study.
The lesson we keep learning in production is that retrieval quality is not a “set and forget” decision. As document collections grow, as policies update, as user queries evolve, the chunking and retrieval strategy needs to evolve with them. The teams that treat retrieval as a continuously measured, continuously improved system are the ones whose RAG deployments actually reach production and stay there.
FAQ
How big should my chunks be?
For most use cases, 256–512 tokens with 10–20% overlap is a validated starting point (re-validated in February 2026 benchmarks). Smaller chunks (128–256 tokens) work better for precise factual retrieval; larger chunks (512–1024 tokens) work better when the model needs surrounding context to generate coherent answers. The right size depends on your query patterns, so test both and measure recall@k.
Does chunking strategy differ for tables vs. prose?
Yes, substantially. Tables should be extracted as structured units (row-level or block-level) rather than tokenized as flat text. When a table row is split across two chunks, the column headers are lost and the data becomes meaningless to the model. Layout-aware extraction tools handle this by preserving table structure during the chunking stage.
How often should I re-chunk my documents?
Re-chunk whenever source documents are updated, and schedule periodic re-chunking (monthly or quarterly) for living document collections. If your freshness score drops below 95%, stale chunks are actively degrading your retrieval quality. Versioned chunking (where old chunks are deprecated rather than deleted), lets you maintain audit trails while keeping retrieval current.
Can I use the same chunks for different use cases?
You can, but you probably should not. Different use cases often have different query patterns, precision requirements, and context needs. A customer support chatbot and an internal compliance tool querying the same document set may need very different chunk sizes and metadata strategies. Separate chunk stores (or filtered retrieval with metadata) give you the flexibility to optimize each use case independently.
What is the difference between chunking and context window size?
Chunking determines what gets retrieved. The context window determines how much retrieved content the model can process at once. They are complementary, not substitutes. Even with a 128K-token context window, retrieval quality still matters because stuffing the window with irrelevant chunks dilutes the signal. Chroma’s context rot research (2025) found a “context cliff” around 2,500 tokens where response quality drops significantly, confirming that more context is not always better.


